Don't Panic
俗话说得好,用 btrfs 的人不吃一次 ENOSPC 就算人生不完整。Btrfs 巧妙的
chunk 双重分配设计使得你可以在 df 报告 all green 的时候唐突
ENOSPC。不过我一度觉得只要没发生过大规模删除 subvol ,导致 allocation
效率变低这类的情况,唐突 ENOSPC 不会找上你。
万事就怕个但是...
背景
两块盘,hc550(16TB) 和 hc320(8TB),数据是 metadata 用 RAID1, data 用 single。装的快满了,但是剩余空间还剩余接近 2TB。
事件发生
我正在喝着酒儿唱着歌儿,顺便解压一些之前下载的同人音声。突然,解压程序报I/O错误,然后退出。意识到什么地方不对的我直接
dmesg,结果看到吓人的一片红
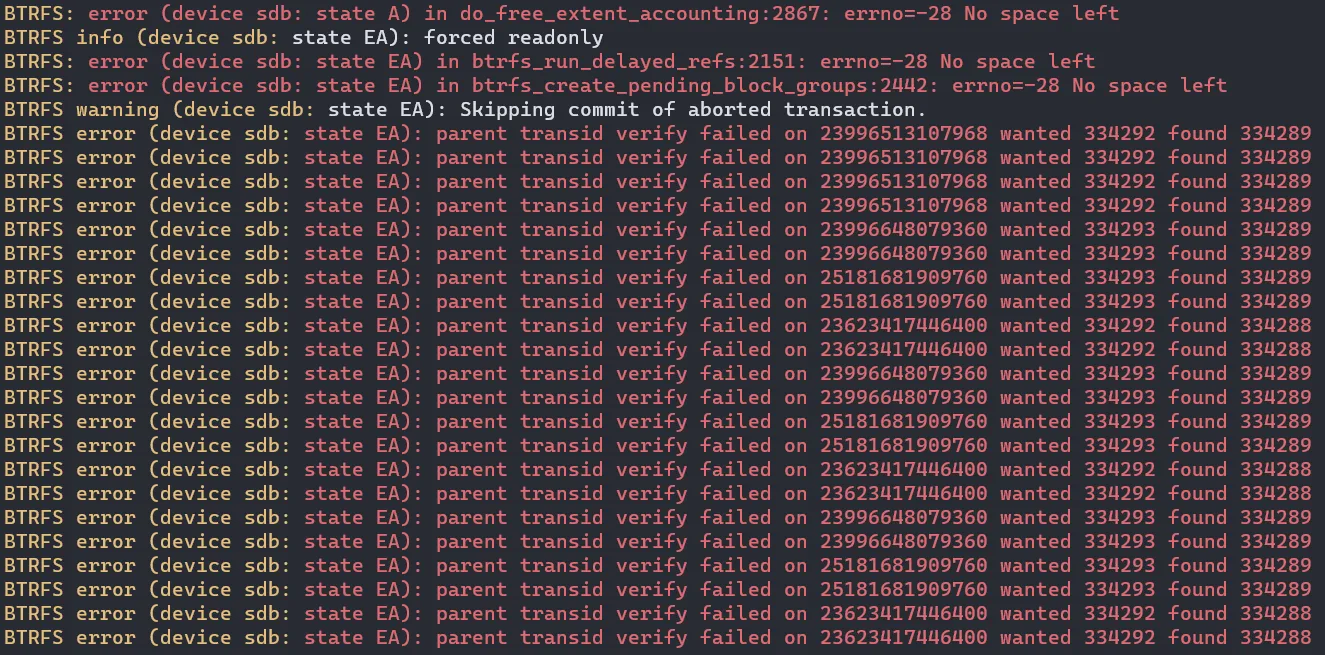
我大概是不熟悉/不信任 btrfs,第一反应看见一堆
transid verify failed,就认为完蛋了不一致了,No space left
我估摸着只是不一致带来的副作用(我的盘整整还有接近2个T的空间呢)。但是总而言之,先隔离影响,断开文件系统。跑一个
btrfs check,分析问题来进行下一步处理。
摇人
跑着 check,不能坐以待毙。于是跑到推特上召唤神奇的马尾,跑到 telegram上召唤神奇的 fc老师,毕竟文件系统出问题修的不对可能扩大问题。
首先得到了 fc老师的回应,和我想的类似,既然 transid 相差不大,那就先直接 check,再看看 backup root 的情况,如果 backup root 能用就直接用它。
马尾接下来识破了问题的本质(感情是 btrfs 开发者,btrfs 怎么谎报军情都了如指掌)
如果 mismatch 只是 abort 的时候出现,那是没啥问题。。。
这之后果然 check 跑完了,一切正常符合预期,那一堆 mismatch 只是误报(或者该 commit 的东西没 commit 进去导致盘上数据和内存里面 pending 的东西不一致?不懂)
解决真正的问题
真正的问题很搞笑,简单地说,剩余空间基本都在16TB那块盘,8TB那块已经基本满了。满了,就没
Unallocated 了,btrfs 想要分配 metadata chunk
就直接失败了(RAID1需要再两块盘都分配空间)。
于是开始想办法解决问题,一开始有这些想法:
- 删除一些文件腾出来空间
- 想办法 balance 走 data
但是删除文件也要CoW metadata,又ENOSPC失败了。并且好不容易成功的删除了文件,这个文件又不在 8TB 的盘上,没起到作用。balance 也没找到办法这样迁移 data chunk。
一气之下,sudo btrfs balance start -mconvert=DUP -msoft ...
直接把元数据变成了 DUP,釜底抽薪,从根本上避免了问题。
结论
- Btrfs 说自己炸了,它不一定真的炸了,要以 btrfs
专家/
btrfs check为准 - Btrfs RAID 在盘容量大小不一样的时候要小心出问题(我一开始以为分配器聪明到能优雅的解决 RAID1 的元数据和 single 的数据之间的占用平衡问题
btrfs fi us /path/to/mount/point是个好东西,没事多看看- Btrfs 大概或许真的没那么容易出现不一致,要相信 CoW 机制,只要马尾等人不写出很严重的 bug,CoW 就能很强的抵御不一致——但是真的很容易 ENOSPC